Martedì 07 Gennaio 2025
area riservata
PlateMatching: la tecnologia alla base dei TUTOR di seconda generazione


I sistemi di rilevamento della velocità media, anche detti TUTOR, di seconda generazione, si caratterizzano per l’utilizzo di Software che implementano la tecnologia PlateMatching in luogo del riconoscimento automatico delle targhe.

Per valutare i vantaggi della tecnologia PlateMatching basti pensare che mentre quando si utilizza il riconoscimento automatico delle targhe per effettuare il controllo della velocità media si identificano univocamente, attraverso il riconoscimento della loro targa, tutti i veicoli in transito presso ciascuno dei due portali di controllo, utilizzando la tecnologia PlateMatching si utilizza una metodologia di rilevazione dell’attraversamento di un veicolo che si basa su di un approccio statistico caratterizzato dalla bassa probabilità di confondere due veicoli in transito in un determinato tratto stradale/autostradale in un breve e ben determinato arco temporale senza la necessità di identificarli univocamente attraverso il riconoscimento esatto della loro targa in ciascuna delle unità periferiche. Ciò consente una maggiore efficienza nella rilevazione delle infrazioni ed una assoluta tutela della privacy degli automobilisti in quanto le targhe non vengono mai riconosciute.
Infatti non è importante identificare il singolo transito presso la singola unità periferica (nel qual caso il sistema sarebbe volto alla localizzazione ed al controllo degli spostamenti dei veicoli) ma il tempo che ha impiegato un veicolo a percorrere il tratto compreso tra le due unità periferiche: basta quindi capire che si tratta dello stesso veicolo senza “sapere inequivocabilmente chi sia”. Una volta individuati i veicoli in sospetta violazione, dopo che le immagini sono state trasmesse sull’unità centrale, un operatore visualizzando le immagini relative ai due attraversamenti potrà visivamente verificare che effettivamente si tratta dello stesso veicolo ed altresì leggere la targa e attivare le necessarie procedure per contestare l’infrazione.
La tecnologia PlateMatching, coperta da ben 38 brevetti, tende ad eliminare degli inconvenienti presenti negli altri sistemi di controllo della velocità media ed in particolare in quelli che utilizzano sistemi di riconoscimento automatico delle targhe che trovano concrete difficoltà in moltissime situazioni che si verificano nella pratica: infatti spesso alcuni caratteri non risultano leggibili per cui la targa non viene riconosciuta e comunque ad oggi è virtualmente impossibile disporre di un affidabile sistema di riconoscimento targhe valido per le diverse tipologie di targa previste nei diversi paesi (non essendo nota a priori la nazionalità del veicolo sarebbe necessario far processare le immagini da differenti moduli di elaborazione specializzati i quali comporterebbero tempi di elaborazione non compatibili con le esigenze del sistema compromettendone l’efficacia).
La figura che segue mostra come differenti caratteri possano venire confusi a causa dei disturbi che possono presentarsi sulle immagini:

si può notare quanto in alcuni casi possa risultare difficile la distinzione tra i caratteri B ed 8 così come 0 (Zero) e D.
La tecnologia di PlateMatching consente di stabilire corrispondenze tra due veicoli transitati presso le unità periferiche con altissima efficacia indipendentemente dalla tipologia e nazionalità delle targhe in quanto tale tecnologia è indipendente dal formato delle targhe e dal font utilizzato dai loro caratteri.
La tecnologia PlateMatching consiste nella capacità di associare i vari elementi della targa (caratteri ed altri simboli) ad elementi di un alfabeto ristretto, l’alfabeto PM, utilizzato per la valutazione delle corrispondenze tra targhe. Viene in pratica applicato un funzionale matematico non biiettivo in grado di mappare i caratteri della targa e gli eventuali altri simboli presenti (ad es. nei camper l’adesivo indicante la nazione, gli eventuali adesivi con limiti di velocità od altri adesivi/contrassegni) in un nuovo alfabeto di dimensioni ristrette, raggruppandoli per classi di similitudine le quali hanno bassa probabilità di essere confuse tra loro.
Ad esempio vengono associati ad uno dei simboli dell’alfabeto PM tutti i caratteri di targhe e contrassegni caratterizzati dal presentare lo stesso tipo di contenuto informativo: ad esempio il primo simbolo dell’alfabeto PM raggruppa {0 (zero), D, O (vocale ‘O’), Q} e sintetizza la caratteristica di “oggetto tondo” che ben si distingue dal simbolo che raggruppa {2, 7, Z} che sintetizza la caratteristica di “oggetto a zig zag”.
Si tratta di uno spazio che raccoglie e sintetizza i caratteri di partenza attraverso le caratteristiche più resistenti alle deformazioni sull’immagine ed essendo caratterizzato da una numerabilità inferiore non rende possibile ritornare all’alfabeto precedente: il funzionale non è biiettivo.
In definitiva quindi si ha un raggruppamento col quale poi diviene possibile il confronto tra i veicoli rappresentati nelle immagini acquisite da due distinte unità periferiche che è reso possibile dal fatto che ai fini dell’individuazione della corrispondenza tra i veicoli non è necessaria l’identificazione esatta della loro targa in ognuno dei due punti di rilevazione del transito ed ovviamente si ha bassa probabilità di errore in quanto gli elementi dell’alfabeto PM sono tali da raggruppare ciascuno classi di caratteri ben distinti tra loro.
Tradotto nella pratica i disturbi presenti sull’immagine in genere inducono una deformazione del carattere attraverso la quale può aumentare la probabilità di confonderlo con un altro, ma il carattere col quale lo si confonderebbe viene mappato (con altissima probabilità) con lo stesso simbolo dell’alfabeto PM e ciò consente di stabilirne la corrispondenza.
Una volta compreso il principio di funzionamento della tecnologia PlateMatching, va chiarito che l’alfabeto PM riceve in ingresso non solamente i caratteri delle targhe italiane standard ma anche quelli delle targhe atipiche (forze di polizia, carabinieri, croce rossa ecc.), targhe degradate, targhe realizzate ad hoc (capita spesso nei rimorchi dei mezzi pesanti) e quelli delle targhe di altre nazioni, in quanto, raggruppati in funzione del contenuto informativo: un carattere ‘A’ di una targa italiana non è molto diverso da quello di una targa tedesca, francese, olandese, ceca, svizzera od altro e ne sintetizza la medesima caratteristica di “oggetto con la punta in alto”: i caratteri di tutte le targhe dei vari paesi vengono mappati nei 19 simboli dell’alfabeto PM. In definitiva quindi un insieme molto molto ampio di caratteri viene mappato dal funzionale non biiettivo PM.
Nella figura che segue è rappresentato lo schema di principio del funzionale non biiettivo PM:
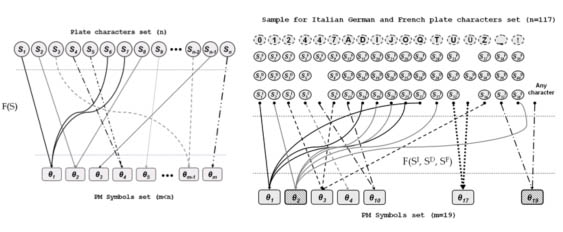
Schematizzazione dell’operatore matematico PM: a sx un generico insieme di caratteri viene mappato in un insieme di simboli dell’alfabeto PM di cardinalità minore. A dx è riportato l’esempio di operatore PM applicato a targhe italiane, tedesche, e francesi
(117 differenti caratteri sono mappati nei 19 simboli dell’alfabeto PM)
Il fatto che il funzionale sia non biiettivo significa che se in un dato stadio del procedimento di analisi delle corrispondenze potessimo accedere ai dati inviati da una stazione trovando ad esempio la sequenza θ11 θ13 θ9 θ3 θ1 θ8 θ16 questa potrebbe corrispondere ad un elevato numero di targhe ( ad es. CK920BR, GV97QFP e tante altre): non è quindi possibile a partire da una stringa nell’alfabeto PM risalire alla targa del veicolo da cui è stata ricavata.
Resta ora da descrivere come avviene il confronto tra stringhe PM.
Ogni transito rilevato su una determinata stazione di rilevamento periferico viene confrontato con i transiti rilevati sull’unità periferica a monte unicamente nell’arco temporale compatibile con le violazioni: tutti i transiti con velocità nei limiti non vengono nemmeno analizzati.
Tipicamente da ogni immagine viene estratta una determinata stringa di caratteri dell’alfabeto PM.
Consideriamo ad esempio le figure che seguono e che rappresentano una possibile rilevazione in due diverse stazioni di monitoraggio (le targhe sono state modificate a tutela della privacy del proprietario),

Esempio di veicolo rilevato da due stazioni periferiche
applicando il procedimento all’immagine destra (relativa al transito presso l’unità periferica di riferimento) otterremo la sequenza:
θ2 θ2 θ11 θ11 θ19 θ6 θ7 θ2 θ16 θ12 θ2 θ2
ottenuta attraverso la seguente mappatura nei caratteri dell’alfabeto PM:
θ2 demarcatore di targa
θ11 carattere G
θ11 carattere G
θ19 spazio/non simbolo
θ6 numero 5
θ7 numero 6
θ2 numero 1
θ16 carattere P
θ12 carattere M
θ2 demarcatore di targa
θ2 stretta porzione di immagine che segue il demarcatore di targa scambiato per una I
applicando il procedimento all’immagine sinistra (relativa al transito presso l’unità periferica a monte) otterremo la sequenza:
θ2 θ11 θ11 θ19 θ6 θ7 θ2 θ16 θ19 θ2
ottenuta attraverso la seguente mappatura nei caratteri dell’alfabeto PM:
θ2 demarcatore di targa
θ11 carattere G
θ11 carattere G
θ19 spazio/non simbolo
θ6 numero 5
θ7 numero 6
θ2 numero 1
θ16 carattere P
θ19 spazio/non simbolo
θ2 demarcatore di targa
notare che:
1) Le due sequenze di caratteri nell’alfabeto PM sono differenti (come in genere accade).
2) Le due sequenze di caratteri nell’alfabeto PM sono di lunghezze differenti (come in genere accade).
Il procedimento di verifica della verosimiglianza delle due sequenze avviene facendo “scorrere” una sull’altra e per ciascuna delle posizioni di scorrimento creando un punteggio di accoppiamento dato dalla seguente formula.
rank = somma (αi x ai x bi) x ε
i=1,..,Cm
dove
Cm è la cardinalità della stringa più corta (nel nostro caso 10)
• αi rappresenta il premio/penalità di accoppiamento/disaccoppiamento per cui se i due simboli confrontati (nello spazio dell’alfabeto PM) sono uguali il fattore moltiplicativo sarà un valore positivo se sono diversi sarà negativo.
• ai e bi rappresentano i livelli di confidenza nell’associazione di un simbolo in ingresso ad un determinato simbolo dell’alfabeto PM. Tali livelli di confidenza dipendono dalla qualità dell’immagine e quindi dal rumore, per cui più “pulito e/o nitido” è il carattere più è elevato il valore di confidenza col quale viene associato ad un determinato simbolo PM.
• ε è un valore di normalizzazione che riporta i valori in una scala prefissata (da 0 ad 1 ad esempio).
Di tutte le posizioni viene selezionata quella che fornisce il punteggio più alto (che corrisponde al confronto migliore, ovvero alla migliore sovrapposizione tra le stringhe) e solo se questo punteggio supera una certa soglia allora i due veicoli raffigurati dalle immagini possono essere accoppiabili.
Se invece tale valore non viene superato da nessuna delle immagini allora non c’è accoppiamento.
Dati sperimentali attestano che nei sistemi di rilevamento della velocità media di seconda generazione, attraverso l’utilizzo della tecnologia PlateMatching è possibile recuperare oltre il 70% degli accoppiamenti persi con un tradizionale sistema di prima generazione basato sul riconoscimento automatico delle targhe.



Volete sapere come funzionerà il Tutor di seconda generazione? Ecco ve lo spieghiamo noi con una scheda che illustra la nuova tecnologia del sistema SICVe – PA (Plate-Matching).
Una esclusiva ASAPS.